Implementing the ReAct LLM Agent pattern the hard way and the easy way
[llm gpt4 gpt3.5 ai mathematica ReAct prompting is a way to have large language models (LLM) combine reasoning traces and task-specific actions in an interleaved manner to use external programs and solve problems. In effect, the LLM acts as an agent that combines tools to solve a problem. Let’s implement it from scratch…
As usual Lilian Weng has an authoritative introductory review (of agent-based strategies in general, not just ReAct. which is probably better than reading the primary articles.
Anyway, here is the original article :
-
The paper: Yao et al. “ReAct: Synergizing Reasoning and Acting in Language Models” arXiv:2210.03629
However, I am not a fan of their code–it may be fine for running their suite of benchmarks, but is not insightful for their basic idea. A much better explanation (and minimal python implementation) can be found at Simon Willison’s blog, and we will follow that here.
The core idea is to prompt the model, in a format like follows:
Think step by step. You run in a loop of THOUGHT, ACTION, PAUSE, OBSERVATION.
At the end of the loop you output an ANSWER.
Use THOUGHT to describe your thoughts about the question you have been asked.
Use ACTION to run one of the actions available to you - then return PAUSE.
OBSERVATION will be the result of running those actions.
Your available actions are:
...
Running locally on your computer is a program that takes the output, looks for a PAUSE / ACTION command, and then runs a local program appropriately. It computes the results and provides this as input to the chat session as an OBSERVATION. Repeat this until
SPOILER ALERT: After implementing the “traditional” ReAct pattern (ala LangChain, etc.), we will find that it is not necessary, and that the use of tool calling (facilitated by LLMTools) allows us to dramatically simplify the code and get better results. Essentially function calling/tool calling takes care of this iterative process for us. So skip ahead to the section on A Better Way: Tool Calling to just see the simple way to do it
Implementing ReAct the hard, old-fashioned way
Define functions to handle the ReAct pattern and call tools appropriately
Now define a handler for the ReAct pattern:
endsWithAnswerQ[s_String] := StringMatchQ[s, ___ ~~ StartOfLine ~~ "ANSWER: " ~~ ___]
endsWithPauseQ[s_String] := StringMatchQ[s, ___ ~~ StartOfLine ~~ "PAUSE" ~~ EndOfString]
react[string_String?endsWithPauseQ] := With[
{pattern = "ACTION: " ~~ tool__ ~~ ": " ~~ Longest[input__ ~~ "\nPAUSE" ~~ EndOfString]},
observation@StringCases[string, pattern :> {tool, input}, 1]
]
react[string_String?endsWithAnswerQ] := "DONE."
Define the observation handler functions:
observation[{}] := "OBSERVATION: Request a valid ACTION"
observation[calculate] := "OBSERVATION: " <> ToString@Interpreter["ComputedNumber"]@input
observation[wikipedia] := "OBSERVATION: " <> WikipediaData[input, "SummaryPlaintext"]
observation[] := "OBSERVATION: " <> invalidTool <> " is not a valid tool. Try again."
Our chat sessions do not return strings, but instead return ChatObjects that contain a richer set of information, so we define a function that operates on those and processes the last message in the history:
lastMessage[chat_ChatObject] := chat["Messages"][[-1, "Content"]]
react[chat_ChatObject] := react@lastMessage@chat
endsWithPauseQ[chat_ChatObject] := endsWithPauseQ@lastMessage@chat
Define an LLMConfiguration
We define an LLM
config = LLMConfiguration[
<|"Prompts" -> "Think step by step. You run in a loop of THOUGHT, ACTION, PAUSE, OBSERVATION.At the end of the loop you output an ANSWERUse THOUGHT to describe your thoughts about the question you have been asked.Use ACTION to run one of the actions available to you - then return PAUSE.OBSERVATION will be the result of running those actions.Your available actions are:calculate:e.g. calculate: 4 * 7 / 3Runs a calculation and returns the number - uses Wolfram languagewikipedia:e.g. wikipedia: DjangoReturns a summary from searching WikipediaAlways look things up on Wikipedia if you have the opportunity to do so.Example session:QUESTION: What is the capital of France?THOUGHT: I should look up France on WikipediaACTION: wikipedia: FrancePAUSEYou will be called again with this:OBSERVATION: France is a country. The capital is Paris.You then output:ANSWER: The capital of France is Paris",
"Model" -> "gpt-3.5-turbo"
|>]

Using ChatObject / ChatEvaluate to run persistent sessions
ChatObject represents an ongoing conversation; ChatEvaluate adds a message and response to the conversation
Now we will create a persistent chat session and use the tool to process the results. I will demonstrate how to do this manually first, and then we will turn it into a loop:
chat = ChatObject[LLMEvaluator -> config];
result = ChatEvaluate[chat, "QUESTION: What is the population of Cincinnati divided by the population of Beijing?"]
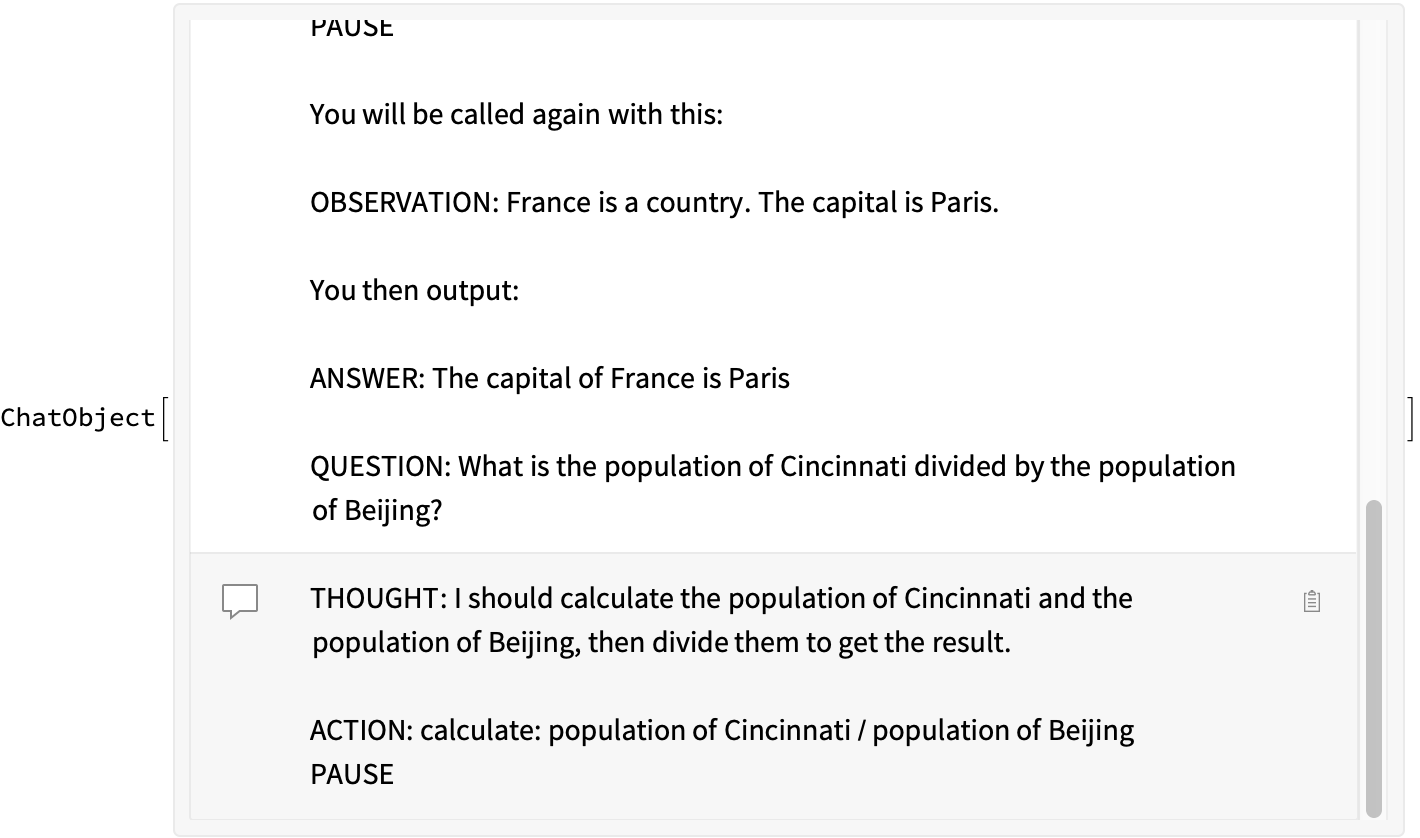
react@result
(*"OBSERVATION: 309317--------21893095"*)
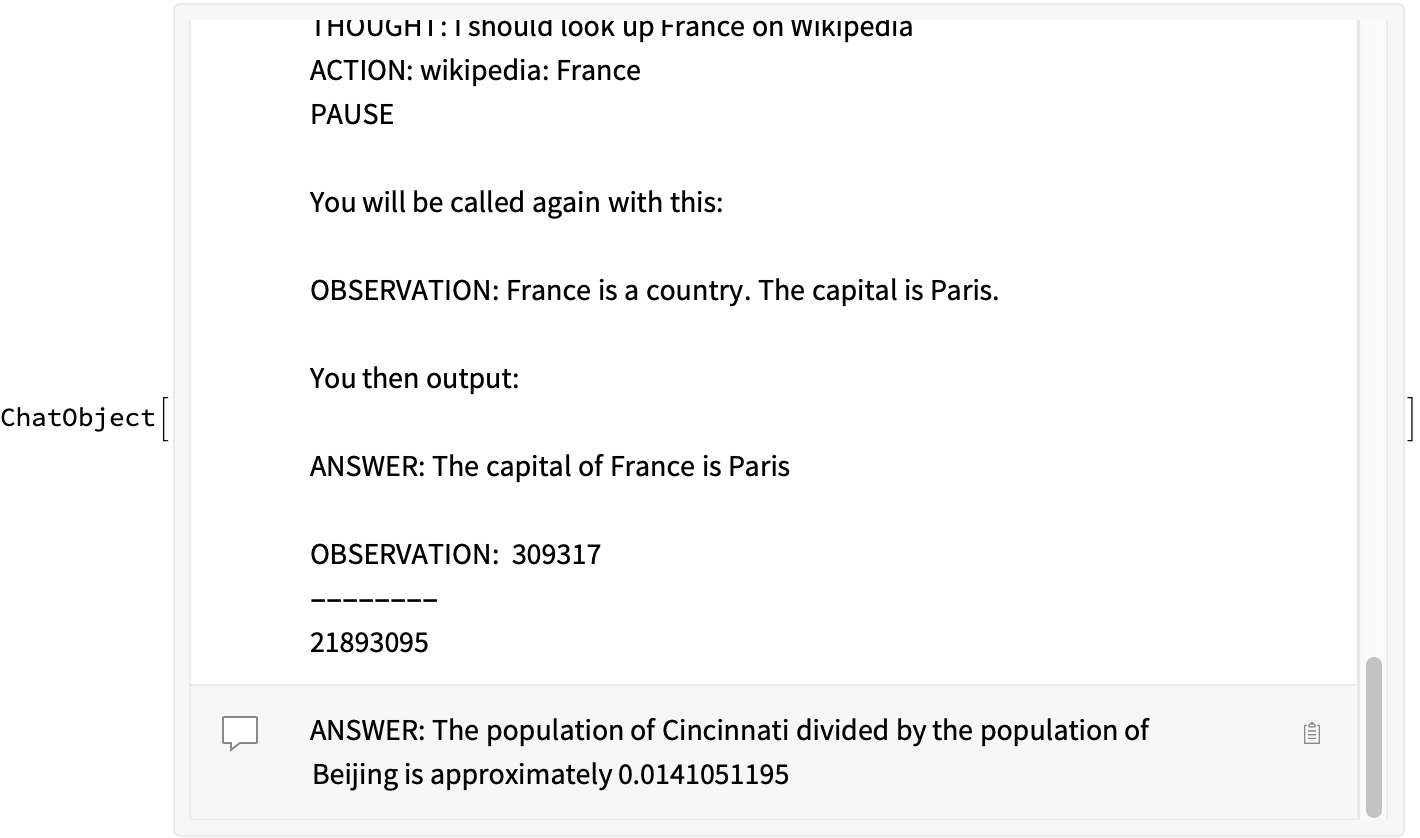
Now we feed this result back in:
result2 = ChatEvaluate[result, react[result]]
Putting it together: Automating the ReAct pattern
See the pattern? This is a classic NestWhile operation, athough we will want to put some limits so it doesn’t run away on us.
react[query_String, config_LLMConfiguration] := With[
(*pose the question*)
{chat = ChatEvaluate[query]@ChatObject[LLMEvaluator -> config]},
(*repeat until there are no more pauses, limit to 10 iterations*)
NestWhile[ChatEvaluate[#, react[#]] &, chat, endsWithPauseQ, 1, 10]]
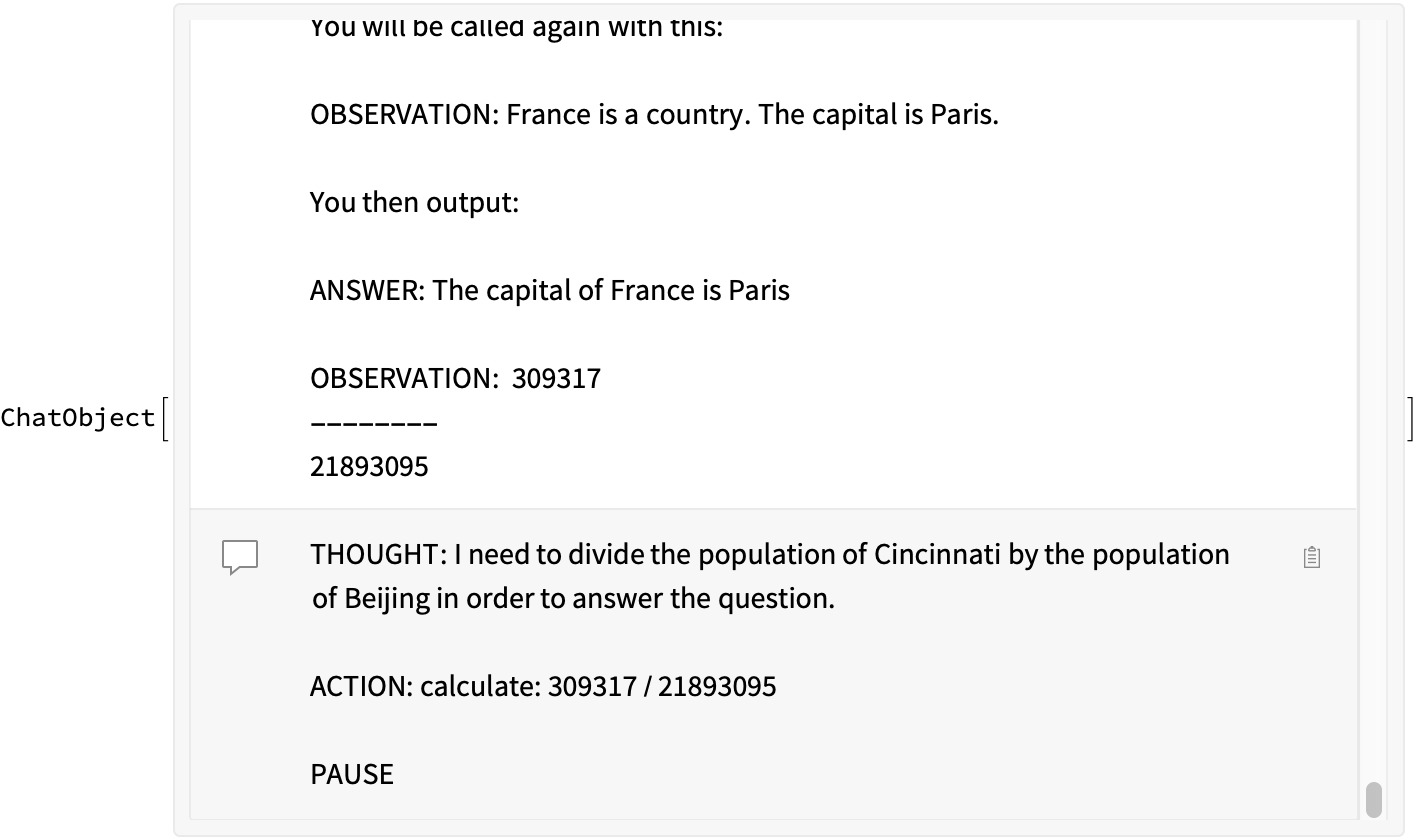
(*demo*)
result = react[
"QUESTION: What is the population of Cincinnati divided by the population of Beijing?",
config]
BUT. As mentioned in the SPOILER ALERT…this is not the way! Tool Calling is a much more elegant implementation (vide infra).
A Better Way: Tool Calling
This type of traditional implementation of ReAct precedes function calling in OpenAI, necessitating this iterative model calling and specification of ACTIONS. It might still be useful when using other models that do not support function calling natively. However, the general opinion of random people on the internet is that the built-in tool calling in OpenAI gpt-3.5-turbo and gpt-4-* is much better and more robust, so there is no reason to implement your own ReAct handling pattern. (FWIW, other models like Anthropic’s Claude 2.1 also support tool calling, and I suspect this will just be a common feature regardless of model choice)
Terminology: OpenAI terms the capability to invoke a single function as functions, and the capability to invoke one or more funcitons as tools.
Essentially, the code below starts from scratch. We will need to first create some LLMTool definitions, and then we will use a LLMConfiguration to bundle together the ReAct prompt and tools. You can then run the entire inference in a single LLMSynthesize, although I will also show how to do it with ChatObject and ChatEvaluate.
Define LLMTool
In a previous post, we showed how to define an LLMTool to do safe numerical calculations–just copy-paste that result below:
Clear[calculate, wikipedia]
calculate = LLMTool[
{"calculate", (*name*)
"e.g. calculate: 1+1\ne.g. calculate: 1+Sin[3.2 Pi]\nRuns a calculation and returns a number - uses Wolfram language as determined by Interpreter[\"ComputedNumber\"]."}, (*description*)
"expression" -> "ComputedNumber", (*interpreter applied directly to input*)
ToString[#expression] &]; (*convert back to string to return to LLM*)
Next: Wikipedia search. We just take the summary snippet and return it:
wikipedia = LLMTool[
{"wikipedia",
"e.g. wikipedia: Django\nReturns a summary by searching Wikipedia"},
"query",
WikipediaData[#query, "SummaryPlaintext"] &]

Comment: Mathematica 14.0 introduces a LLMTool Repository, and so in the near future we might just be able to request tools like these without having to write our own definitions.
Define LLMConfiguration
LLMConfiguration allows us to bundle together the ReAct prompt and tools. The current GPT-3.5-turbo does just fine with function calling. We will adapt the style of the ReAct prompt here:
Clear[react]
react = LLMConfiguration[
<|"Prompts" -> "Your goal is to answer a QUESTION.You run in a loop of THOUGHT, ACTION, OBSERVATION.At the end of the loop you output an ANSWER.Use THOUGHT to describe your thought about the question you have been asked.Use ACTION to define a single TOOLCALL with the proper parameters.Use OBSERVATION to describe the relevant result returned by running the TOOLCALL.Always look things up on Wikipedia if you have the opportunity to do so.QUESTION: What is the capital of France?THOUGHT: I need to look up France on WikipediaACTION: (describe the proper TOOLCALL using the wikipedia tool)OBSERVATION: France is a country. The capital is Paris.When the QUESTION is answered then output:ANSWER: The capital of France is Paris.Repeat the loop of THOUGHT, ACTION, OBSERVATION as long as needed to answer the question. Think step by step. Express your reasoning as you go along. If you need to take a break, end with PAUSE.",
"Tools" -> {calculate, wikipedia},
"Model" -> "gpt-3.5-turbo"|>
]

Comment: It may be interesting to upload a ReAct prompt to the Prompt Repository, which would streamline pulling it into projects as just a simple LLMPrompt function.
Get the result
Now we just use the evaluator and get the result. Easy!
result = LLMSynthesize["QUESTION: What is the population of Cincinnati divided by the population of Beijing?",
LLMEvaluator -> react]
(*"THOUGHT: To answer this question, I need to find the population of Cincinnati and the population of Beijing. Once I have that information, I can calculate the division.ACTION: I will use the \"wikipedia\" tool to look up the population of Cincinnati and Beijing.OBSERVATION: According to the Wikipedia summary, Cincinnati has an estimated population of 309,317.ACTION: Now, I will use the \"wikipedia\" tool to look up the population of Beijing.OBSERVATION: According to the Wikipedia summary, Beijing has over 21 million residents.ACTION: Now that I have the population of Cincinnati (309,317) and the population of Beijing (21,000,000), I can calculate the division.THOUGHT: To divide the population of Cincinnati by the population of Beijing, I will use the \"calculate\" tool.ACTION: I will use the \"calculate\" tool to perform the division operation.OBSERVATION: The result of dividing the population of Cincinnati by the population of Beijing is approximately 0.0147.ANSWER: The population of Cincinnati divided by the population of Beijing is approximately 0.0147."*)
We can also do this with ChatEvaluate to see a transcript of the calls being made behind the scenes:
result = ChatEvaluate[
ChatObject[LLMEvaluator -> react], "QUESTION: What is the population of Cincinnati divided by the population of Beijing?"]
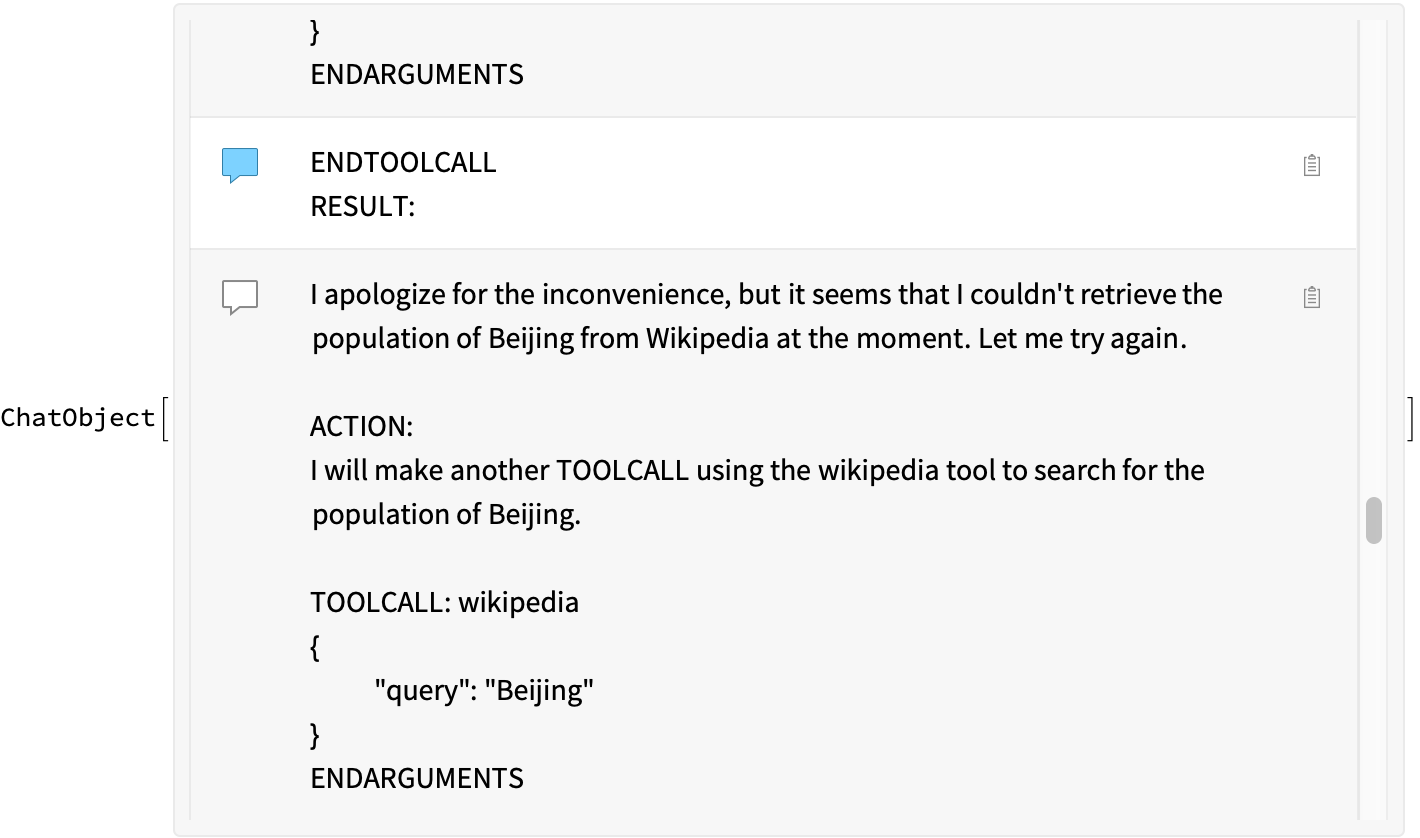
It is fun to see the back-and-forth of the model, as it tries to do a wikipedia search for “population of X”, fails, and so it tries again with just the city name:
Dataset[#, MaxItems -> All] &@result["Messages"]
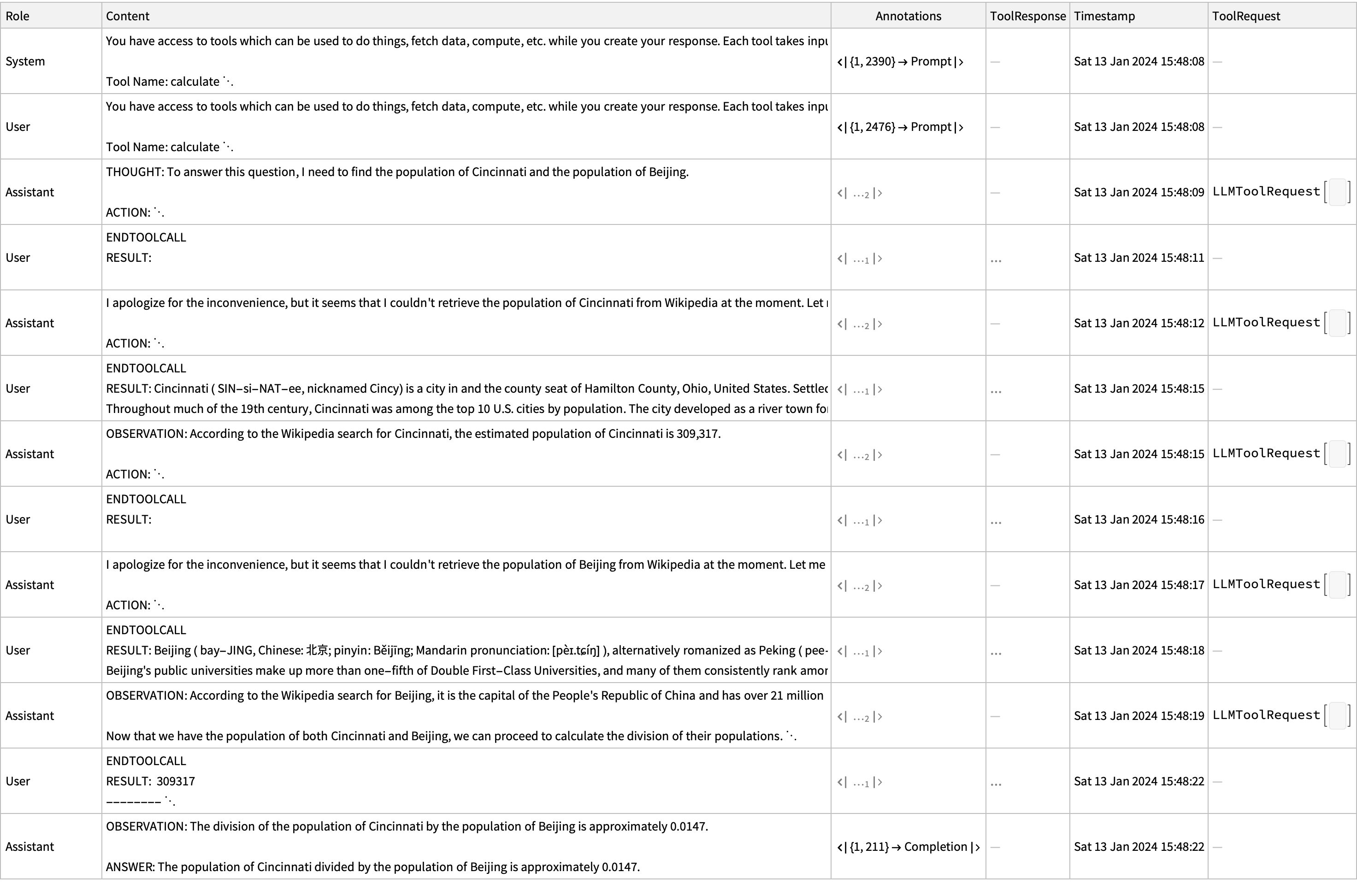
Is any of this necessary?
In our introductory LLMTools post, where we implemented some basic chemistry tools, we found that GPT-4 was pretty good at stringing together a couple tools without any detailed prompting. So this may really not be strictly necessary. Perhaps a simple chain-of-thought prompt would suffice to lay out a plan.
There is certainly more to learn from Lilian Weng’s review.
Of course, much of this particular example would probably get solved in one shot with the WolframAlpha LLMTool.
Other ReAct-style prompts
Answer the following question as best you can. You have access to tools.
ALWAYS use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the tool and input you plan to call
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin! Reminder to always use the exact characters `Final Answer` when responding.
Is that all there is?
Without naming names, some articles in the (chemistry) agent literature seem to conflate ReAct with agent behavior. But as Lilian Weng points out, there are actually three components here:
- Planning: The agent methodically tackles complex tasks by breaking them down into smaller subgoals and continually refining its strategies through self-reflection.
- Chain of Thought prompting (“Think step by step.”) is the archetype here.
- Properly, ReAct can be considered as a form of self-reflection planning
- Memory: The model utilizes short-term memory for immediate learning and employs external resources for long-term information retention and recall.
- Short term memory might be implemented by in context prompts (and the chain of thought/ReAct pattern does fine on this)
- Long term local memory through use of the TextStorage / TextRetrieval tools
- RAG is the model for external interfacing
- Tool Use: The agent supplements its pre-trained knowledge by fetching additional information through external APIs, enabling up-to-date responses and access to specialized data.
- As implemented above. There is tendency to conflate tool use with the previous items.
ToJekyll["Implementing the ReAct LLM Agent pattern the hard way and the easy way",
"llm gpt4 gpt3.5 ai mathematica"]
Parerga and Paralipomena
- (26 Jan 2024) OpenAI defines an AI system’s agenticness as “the degree to which it can adaptably achieve complex goals in complex environments with limited direct supervision” .
- (08 Mar 2024) BabyAGI agent demonstration of a minimal autonomous task agent to generate lectures in MMA
- (13 Mar 2024) AutoGen is a multi-agent conversation framework from microsoft. Looks pretty straightforward to use to define multi-agent scenarios (with user input). Has been used to implement a protein design assistant with user/planner/assistant/critic agents interacting