Predicting lithium-metal battery interface stability with o1-mini and o1-preview
[gpt4 o1 llm science mathematica Recently there has been a lot of excitement about the new OpenAI o1 and o1-mini models. Back in October 2024, I explored of the use of the preview versions of these models to perform reasoning about low-data problems in materials science, specifically predicting stable lithium metal interfaces for batteries, and using some of the rule extraction workflows demonstrated previously. We didn’t pursue this project further, so to close out the year I am posting this preliminary exploratory example to illustrate the strategy and performance…
Premise: Can we use an LLM workflow to predict the stability of material-Lithium metal interfaces in batteries, based on a very small training set? This work is inspired by (and takes data from Lomeli et al. 2024 who used ab initio MD simulations to generate a 50-item training set (used below), and then built some linear models.
Experiment: For simplicity we will only try a single cross-validation for each model type using their 50-item training set (so 40 training items and 10 test items). Finally, we will train on all 50 training items and try to predict their 17 item validation set.
Key findings: (tl;dr)
-
GPT-4o in-context learning on composition only (formula) is unimpressive on the training data–results are comparable to guessing–but does comparable to Lomeli’s model when applied to the validation set (about 65% accuracy)
-
o1-mini to generate chemical “rules” based on the examples and then apply them to make predictions is similarly unimpressive on the training data, but does better than Lomeli’s model on the validation set (75% accuracy)
-
o1-preview to generate rules and make predictions relies more on aspects of the text inputs rather than general principles, and result is comparable to the bespoke logistic-regression + selected features used in the paper.
Questions about the source paper
The training data is in Table 1 and consists of 50 items. The authors explore a classifier approach in which they use logistic regression models to make a “reactive model” (SM) to differentiate between stable and reactive/passivating materials, and an “unreactive model” (RM) to differentiate between stable/passivating and reactive materials. We will only implement the first one here as a check.
They create their models through a 5-fold cross validation, with results reported in Figure 2 (reproduced below). However, something seems odd to me, in that they perform a 5-fold cross validation (good), but only show one line? I’m guessing this is the average of their cross-validation runs (but why not show error bars)? Unfortunately, they don’t provide any source code, so it’s hard to say what they are actually doing.

Data Preparation
SetDirectory@NotebookDirectory[];
data = Import["./data/training.csv", "Dataset", HeaderLines -> 1];
stableQ[entry_String] := StringMatchQ["stable"]@entry
stableQ[entry_Association] := stableQ@entry["label"]
unreactiveQ[entry_String] := StringMatchQ[{"stable", "passivating"}]@entry
unreactiveQ[entry_Association] := unreactiveQ@entry["label"]
stableData = data[All, {"label" -> stableQ}][All, {"composition", "label"}];
SeedRandom[1884];
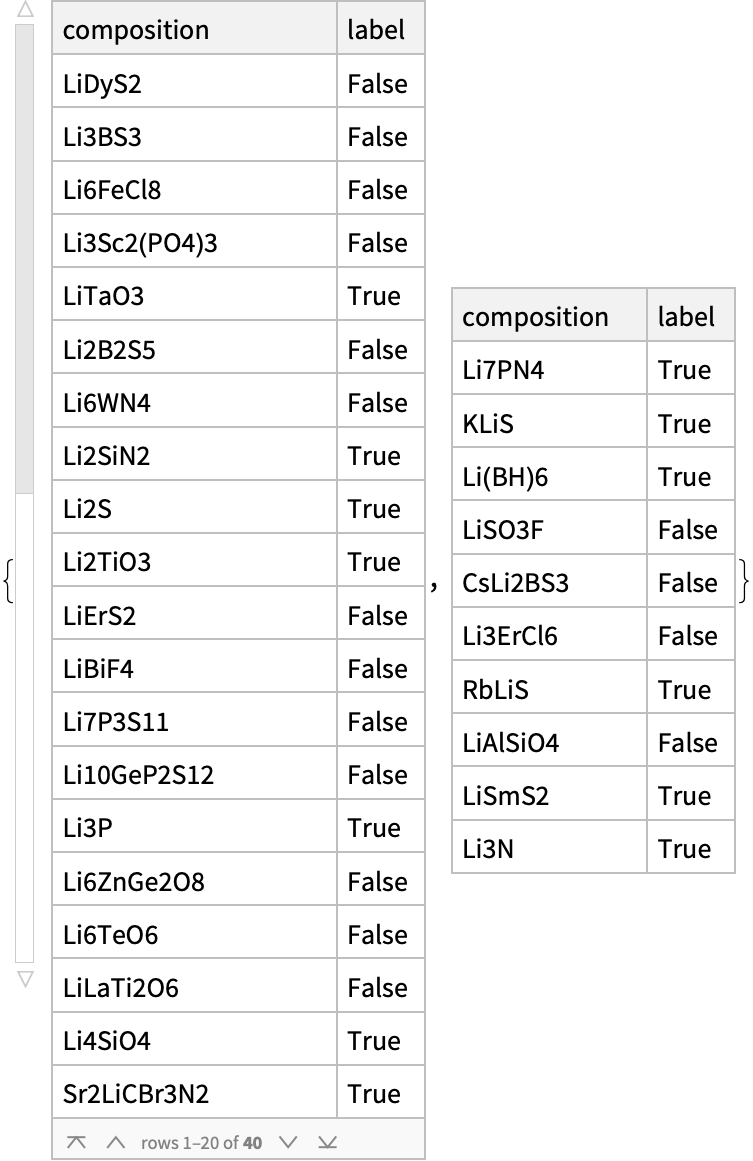
{train, test} = ResourceFunction["TrainTestSplit"][stableData]
GPT-4o In-Context Learning is unimpressive
Create a list of examples and provide in-context to gpt-4o:
examples = Rule @@@ Normal@Values@train
{“LiDyS2” -> False, “Li3BS3” -> False, “Li6FeCl8” -> False, “Li3Sc2(PO4)3” -> False, “LiTaO3” -> True, “Li2B2S5” -> False, “Li6WN4” -> False, “Li2SiN2” -> True, “Li2S” -> True, “Li2TiO3” -> True, “LiErS2” -> False, “LiBiF4” -> False, “Li7P3S11” -> False, “Li10GeP2S12” -> False, “Li3P” -> True, “Li6ZnGe2O8” -> False, “Li6TeO6” -> False, “LiLaTi2O6” -> False, “Li4SiO4” -> True, “Sr2LiCBr3N2” -> True, “BaLiBS3” -> False, “LiGaCl3” -> False, “Li2GePbS4” -> False, “Li2PNO2” -> True, “LiHoS2” -> False, “Li3InCl6” -> False, “LiScTl2Cl6” -> False, “Li7La3Zr2O12” -> True, “LiGa(PO3)4” -> False, “LiMnPO4” -> False, “Li3VO4” -> True, “Li2TiSiO5” -> False, “Li7VGeO8” -> True, “LiErSe2” -> False, “Li6NBr3” -> True, “NaLiSe” -> False, “Li3PS4” -> False, “Li3Fe2(PO4)3” -> False, “LiMgN” -> True, “LiSnPO4” -> False}*)
stableLLMQ = LLMExampleFunction[{"You are an expert solid state chemist. Will this material with this chemical formula form a stable interface with metallic lithium metal?",
examples},
"Boolean",
LLMEvaluator -> <|"Model" -> "gpt-4o-2024-08-06", "Temperature" -> 1|>];
Evaluate predictions:
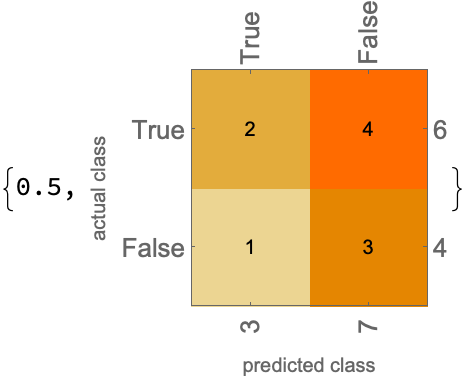
predictions = stableLLMQ /@ Normal@test[[All, "composition"]];
actual = Normal@test[[All, "label"]];
ClassifierMeasurements[predictions, actual,
{"Accuracy", "ConfusionMatrixPlot"}]
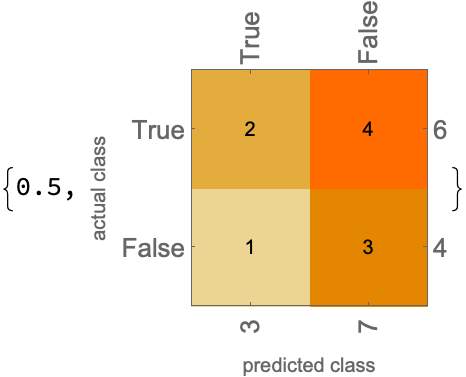
Lowering the temperature does not improve the results:
stableLLMQ = LLMExampleFunction[{"You are an expert solid state chemist. Will this material with this chemical formula form a stable interface with metallic lithium metal?",
examples},
"Boolean",
LLMEvaluator -> <|"Model" -> "gpt-4o-2024-08-06", "Temperature" -> 0|>];
predictions = stableLLMQ /@ Normal@test[[All, "composition"]];
ClassifierMeasurements[predictions, actual,
{"Accuracy", "ConfusionMatrixPlot"}]
Test of o1-mini
Premise: Use the reasoning capability of o1-mini to generate explainable rules about the training data and then apply it to tests cases:
Rule Generation
This is an ugly hack, just to see how well this works. Proposed workflow is to generate rules:
input = StringTemplate["You are an expert solid state chemist studying the stability of interfaces of materials with metallic lithium. Formulate general rules that could be used to predict the stability of a new material based on the following observations:The following compounds form a stable interfaces: ``The following compounds for unstable interfaces: ``"] @@ Lookup[{True, False}]@Map[StringRiffle]@Normal@train[GroupBy["label"], All, "composition"]
“You are an expert solid state chemist studying the stability of interfaces of materials with metallic lithium. Formulate general rules that could be used to predict the stability of a new material based on the following observations:The following compounds form a stable interfaces: LiTaO3 Li2SiN2 Li2S Li2TiO3 Li3P Li4SiO4 Sr2LiCBr3N2 Li2PNO2 Li7La3Zr2O12 Li3VO4 Li7VGeO8 Li6NBr3 LiMgNThe following compounds for unstable interfaces: LiDyS2 Li3BS3 Li6FeCl8 Li3Sc2(PO4)3 Li2B2S5 Li6WN4 LiErS2 LiBiF4 Li7P3S11 Li10GeP2S12 Li6ZnGe2O8 Li6TeO6 LiLaTi2O6 BaLiBS3 LiGaCl3 Li2GePbS4 LiHoS2 Li3InCl6 LiScTl2Cl6 LiGa(PO3)4 LiMnPO4 Li2TiSiO5 LiErSe2 NaLiSe Li3PS4 Li3Fe2(PO4)3 LiSnPO4”
Generated explanation:
chat = ServiceExecute["OpenAI", "Chat",
{"Messages" -> {<|"Role" -> "user", "Content" -> input|>},
"Model" -> "o1-mini-2024-09-12", "Temperature" -> 1}]

Combined Rule Generation and Prediction:
Try to make the predictions directly:
input2 = With[
{examples = Map[StringRiffle]@Normal@train[GroupBy["label"], All, "composition"],
predictions = StringRiffle@Normal@test[[All, "composition"]]},
StringTemplate["You are an expert solid state chemist studying the stability of interfaces of materials with metallic lithium. Formulate general rules that could be used to predict the stability of a new material based on the following observations:The following compounds form a stable interfaces: ``The following compounds for unstable interfaces: ``Then apply your rules to make predictions for the following compounds: ``Finally, summarize the predictions for the new compounds as a JSON list with the name of each compound and True (if stable) and False (if unstable). "][examples[True], examples[False], predictions]]
chat2 = ServiceExecute["OpenAI", "Chat",
{"Messages" -> {<|"Role" -> "user", "Content" -> input2|>},
"Model" -> "o1-mini-2024-09-12", "Temperature" -> 1}]
(*"You are an expert solid state chemist studying the stability of interfaces of materials with metallic lithium. Formulate general rules that could be used to predict the stability of a new material based on the following observations:The following compounds form a stable interfaces: LiTaO3 Li2SiN2 Li2S Li2TiO3 Li3P Li4SiO4 Sr2LiCBr3N2 Li2PNO2 Li7La3Zr2O12 Li3VO4 Li7VGeO8 Li6NBr3 LiMgNThe following compounds for unstable interfaces: LiDyS2 Li3BS3 Li6FeCl8 Li3Sc2(PO4)3 Li2B2S5 Li6WN4 LiErS2 LiBiF4 Li7P3S11 Li10GeP2S12 Li6ZnGe2O8 Li6TeO6 LiLaTi2O6 BaLiBS3 LiGaCl3 Li2GePbS4 LiHoS2 Li3InCl6 LiScTl2Cl6 LiGa(PO3)4 LiMnPO4 Li2TiSiO5 LiErSe2 NaLiSe Li3PS4 Li3Fe2(PO4)3 LiSnPO4Then apply your rules to make predictions for the following compounds: Li7PN4 KLiS Li(BH)6 LiSO3F CsLi2BS3 Li3ErCl6 RbLiS LiAlSiO4 LiSmS2 Li3NFinally, summarize the predictions for the new compounds as a JSON list with the name of each compound and True (if stable) and False (if unstable). "*)

predictions2 = {True, False, False, False, False, False, False, True, False, True};
ClassifierMeasurements[predictions2, actual,
{"Accuracy", "ConfusionMatrixPlot"}]
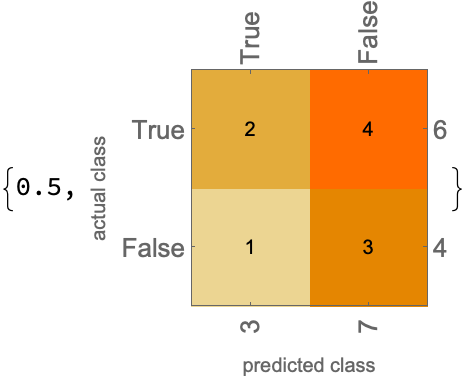
Conclusion: This is not better than the ICL results.
Test of o1-preview
What about if we use o1-preview instead? We will use the same input user prompt as above. Comparing the outputs, the o1-mini explanations above tend to rely on more general principles, whereas the o1-preview explanations below tend to focus more explicitly on the data at hand, and this improves the performance:
chat2a = ServiceExecute["OpenAI", "Chat",
{"Messages" -> {<|"Role" -> "user", "Content" -> input2|>},
"Model" -> "o1-preview-2024-09-12", "Temperature" -> 1}]

predictions2a = {True, True, False, False, False, False, True, True, False, True};
ClassifierMeasurements[%, actual,
{"Accuracy", "ConfusionMatrixPlot"}]
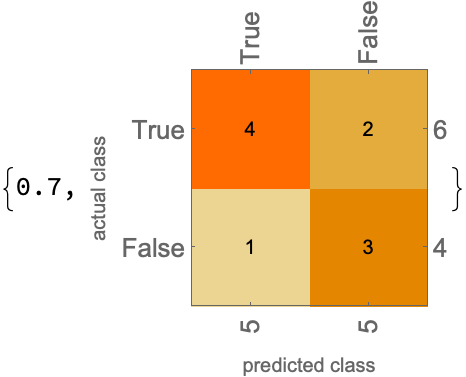
Conclusion: o1-preview improve the performance. For this single fold we get a 30% misclassification rate, which is worse than the results they show in figure 2, but better than what they show in their final test (35% misclassification in Table 2). A more rigorous result would perform the full cross validation
Extrapolation test of o1-preview:
Extrapolate to the validation set used by Lomeli et al. Their models are only 65% accurate:
validation = Import["./data/validation.csv", "Dataset", HeaderLines -> 1][All, {"label" -> stableQ}][All, {"composition", "label"}];
o1-preview is comparable to Lomelli (35% misclassification)
input3 = With[
{examples = Map[StringRiffle]@Normal@stableData[GroupBy["label"], All, "composition"],
predictions = StringRiffle@Normal@validation[[All, "composition"]]},
StringTemplate["You are an expert solid state chemist studying the stability of interfaces of materials with metallic lithium. Formulate general rules that could be used to predict the stability of a new material based on the following observations:The following compounds form a stable interfaces: ``The following compounds for unstable interfaces: ``Then apply your rules to make predictions for the following compounds: ``Finally, summarize the predictions for the new compounds as a JSON list with the name of each compound and True (if stable) and False (if unstable). "][examples[True], examples[False], predictions]]
(*"You are an expert solid state chemist studying the stability of interfaces of materials with metallic lithium. Formulate general rules that could be used to predict the stability of a new material based on the following observations:The following compounds form a stable interfaces: Li6NBr3 Li2S Li7PN4 Li3N LiMgN Li3P Sr2LiCBr3N2 Li7La3Zr2O12 Li2SiN2 Li2TiO3 KLiS Li4SiO4 RbLiS Li(BH)6 LiSmS2 LiTaO3 Li2PNO2 Li3VO4 Li7VGeO8The following compounds for unstable interfaces: Li6WN4 NaLiSe LiErSe2 LiErS2 LiHoS2 LiDyS2 Li2TiSiO5 LiAlSiO4 Li6FeCl8 Li3Sc2(PO4)3 Li3ErCl6 LiLaTi2O6 CsLi2BS3 LiScTl2Cl6 Li6ZnGe2O8 Li3BS3 Li3InCl6 LiSnPO4 BaLiBS3 LiMnPO4 LiGaCl3 Li6TeO6 Li3Fe2(PO4)3 Li10GeP2S12 Li2GePbS4 Li3PS4 LiGa(PO3)4 Li2B2S5 Li7P3S11 LiBiF4 LiSO3FThen apply your rules to make predictions for the following compounds: LiCaAlN2 LiSiB6 LiB12PC LiB13C2 Li7SbN4 LiBeP LiGe2N3 K3LiSi4 Na2LiAlP2 K2LiAlP2 LiMgP Li2HIO LiAlH4 LiGaH4 Li4TiS4 Li5BiS4 Li4SnSe4Finally, summarize the predictions for the new compounds as a JSON list with the name of each compound and True (if stable) and False (if unstable). "*)
chat3 = ServiceExecute["OpenAI", "Chat",
{"Messages" -> {<|"Role" -> "user", "Content" -> input3|>},
"Model" -> "o1-preview-2024-09-12", "Temperature" -> 1}]

predictions3 = {True, True, True, True, False, True, False, True, True, True, True, False, False, False, False, False, False};
actual3 = Normal@validation[All, "label"];
ClassifierMeasurements[predictions3, actual3,
{"Accuracy", "ConfusionMatrixPlot"}]
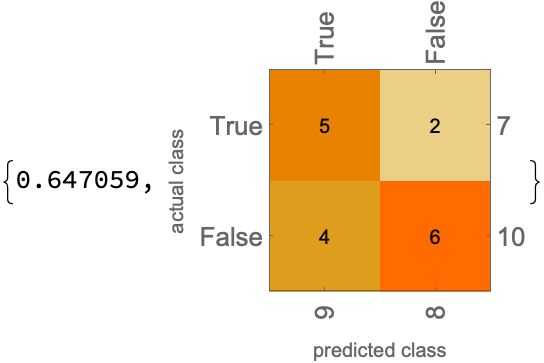
Results are about the same as results as reported in Lomelli (65% accuracy)
o1-mini does better on the validation set (~25% misclassification)
chat3mini = ServiceExecute["OpenAI", "Chat",
{"Messages" -> {<|"Role" -> "user", "Content" -> input3|>},
"Model" -> "o1-mini-2024-09-12", "Temperature" -> 1}]

predictions3mini = {True, True, True, True, True, True, True, True, True, True, True, False, False, False, False, False, False};
ClassifierMeasurements[predictions3mini, actual3,
{"Accuracy", "ConfusionMatrixPlot"}]
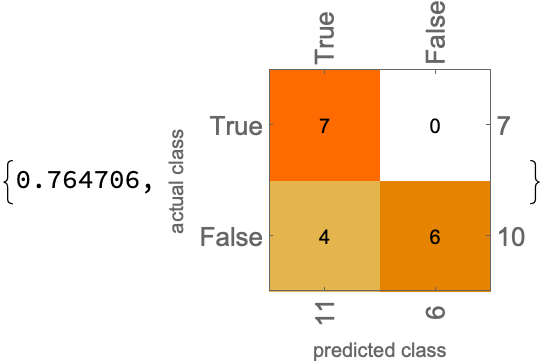
ICL with gpt-4o is also comparable to Lomeli (30% misclassification)
Just copy and paste this code from before, but redefine examples to have all of the training examples, and then and then apply to the validation questions)
examples = Rule @@@ Normal@Values@stableData;
questions = Normal@validation[All, "composition"];
stableLLMQ = LLMExampleFunction[{"You are an expert solid state chemist. Will this material with this chemical formula form a stable interface with metallic lithium metal?",
examples},
"Boolean",
LLMEvaluator -> <|"Model" -> "gpt-4o-2024-08-06", "Temperature" -> 1|>];
predictions3a = stableLLMQ /@ questions
(*{True, False, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False}*)
ClassifierMeasurements[predictions3a, actual3,
{"Accuracy", "ConfusionMatrixPlot"}]
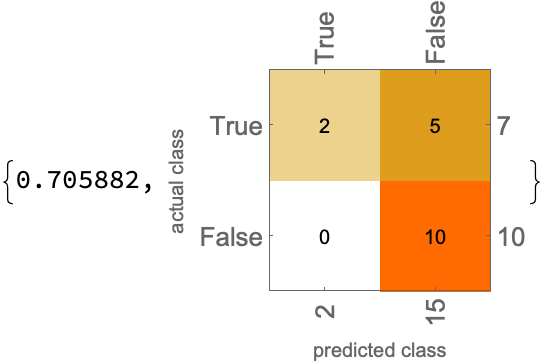
Conclusion: ICL is about the same (maybe a bit better), but definitely leans towards false negatives, rather than being balanced in its predictions. There may be value in combining predictions of the different approaches.
Ideas for future work
-
Calculations above used only a single train/test split–complete the full cross-validation, etc. to be more rigorous. Perhaps we got a bad cross validation?
-
Try including stability energy into the decision making process as an input–as illustrated in the Figure 2, this is not foolproof but does help a lot.
-
Try including structural information (Robocrystallographer) like in our Angewandte Chemie paper?
ToJekyll["Predicting lithium-metal battery interface stability with o1-mini and o1-preview",
"gpt4 o1 llm science mathematica"]